VCの場合
VCの場合、文字列を扱うのに CString
クラスを使用します。
先頭へ
// Button1クリック時のイベント処理
void CVC5Dlg::OnButton1()
{
int iwork;
double dwork;
CString swork;
CString swork2;
CString msg;
// Ex.1: 代入、追加、文字コード
swork = "ABC"; // 代入
swork = swork + "DEF"; // 追加
swork = swork + "\xd\xa"; // 文字コード CR+LF
swork = swork + "0123456";
AfxMessageBox( swork, MB_OK | MB_ICONINFORMATION );
// Ex.2: 数値から文字に変換
iwork = 123;
dwork = 456.789;
swork.Format( "iwork=%d", iwork ); // 整数変換
msg = swork + "\xd\xa";
swork.Format( "dwork=%g", dwork ); // 実数変換
msg = msg + swork;
AfxMessageBox( msg, MB_OK | MB_ICONINFORMATION );
// Ex.3: 文字数
// 現バージョンでは2バイト文字を1文字と数える GetLength関数はありません?
// 自作の mbGetLength() で数えます
swork = "ABCあいう";
iwork = mbGetLength( swork ); // 文字数
swork2.Format( "文字数swork.GetLength()=%d", iwork );
msg = swork2;
iwork = swork.GetLength(); // 文字数(バイト数)
msg = msg + "\xd\xa";
swork2.Format( "文字バイト数swork.GetLength()=%d", iwork );
msg = msg + swork2;
AfxMessageBox( msg, MB_OK | MB_ICONINFORMATION );
// Ex.4: 先頭、末尾、中央からの文字列取り出し
// 現バージョンでは2バイト文字を1文字と扱う Left,Right,Mid関数はありません?
// 自作の mbLeft(),mbRight(),mbMid() で文字列取り出しを行います
swork = "ABCあいう";
// 左端(先頭)から
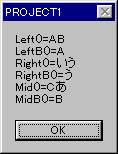
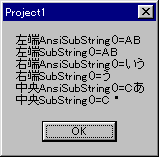
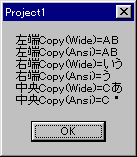
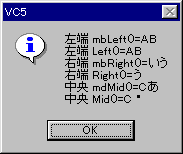
msg = "左端 mbLeft()=" + mbLeft( swork, 2 );
msg = msg + "\xd\xa";
msg = msg + "左端 Left()=" + swork.Left( 2 );
msg = msg + "\xd\xa";
// 右端(末尾)から
msg = msg + "右端 mbRight()=" + mbRight( swork, 2 );
msg = msg + "\xd\xa";
msg = msg + "右端 Right()=" + swork.Right( 2 );
msg = msg + "\xd\xa";
// 中央から
msg = msg + "中央 mdMid()=" + mbMid( swork, 2, 2);
msg = msg + "\xd\xa";
msg = msg + "中央 Mid()=" + swork.Mid( 2, 2);// インデックスは 0 から(文字化けします)
AfxMessageBox( msg, MB_OK | MB_ICONINFORMATION );
// Ex.5: 大文字、小文字
// MakeLower(),MakeUpper()はCString の内容を変更することに注意してください。
swork = "ABCdef";
swork2 = swork;
swork2.MakeLower(); // 小文字変換
msg = "MakeLower()=" + swork2;
msg = msg + "\xd\xa";
swork2 = swork;
swork2.MakeUpper(); // 大文字変換
msg = msg + "MakeUpper()=" + swork2;
AfxMessageBox( msg, MB_OK | MB_ICONINFORMATION );
}
|
//---------------------------------------------------------------------------
// mbGetLength()
// 2バイト文字を1文字と数える、文字数を返します
// [in]
// str : 文字数を数える文字列(CString のみ)
// [out]
// 文字数
// [注意]
// すべての条件で正しい値を返すどうか検証していません
//
int CVC5Dlg::mbGetLength( CString& str )
{
int lenb; // 文字数(バイト数)
int lop; // ループカウンタ
int cnt = 0; // 文字数カウンタ(戻り値)
unsigned int scode; // 1バイト文字コード
unsigned int mcode; // 2バイト文字コード
//// 引数のチェック
lenb = str.GetLength();
if( lenb == 0 )
return cnt; // 空文字の場合
//// メイン処理
for( lop = 0; lop <lenb; lop++ ){ // インデックスは 0 から
// 判断する文字を取り出す
scode = unsigned int( str[ lop ] ) & 0xff;
mcode = unsigned int( str[ lop ] ) & 0xff;
mcode = mcode <<8;
if( (lop + 1) <lenb ) // ASSERT対策:CStringの範囲を越えないように
mcode |= unsigned int( str[ lop + 1 ] ) & 0xff;
mcode &= 0xffff;
// 文字種別の判断
if( __isascii( scode ) != 0 ){
// 1バイト文字
cnt ++;
}
else if( _ismbclegal( mcode ) != 0 ){
// 2バイト文字
cnt ++;
lop ++; // 強引にカウントアップ
}
else{
// 認識できない文字
cnt ++;
}
}
return cnt; // 正常時
}
//---------------------------------------------------------------------------
// mbMid()
// CString 内の指定された部分文字列を返します
// [in]
// str : 部分文字列を取り出す、元の文字列(CString のみ)
// index : 取り出す先頭位置(0~mbGetLength()-1 まで)
// count : 取り出す文字数(2バイト文字も1個と数えます)
// [out]
// 取り出した部分文字列
// [注意]
// この関数はmbGetLength() を利用しています
// index,count が範囲外の場合、空文字を返します
// index+count が文字数を越えている場合、str の終端までを返します
// すべての条件で正しい部分文字列を返すどうか検証していません
//
CString CVC5Dlg::mbMid( CString& str, int index, int count )
{
int len; // 文字数
int lenb; // 文字数(バイト数)
int lop; // ループカウンタ
int cnt = 0; // 文字数カウンタ
int copyCnt = 0; // コピー済み文字数カウンタ
int copyPos = 0; // コピー開始位置
int chrSize; // 1文字のバイト数
unsigned int scode; // 1バイト文字コード
unsigned int mcode; // 2バイト文字コード
CString work = ""; // 取り出した部分文字列(戻り値)
CString nowChr; // 現在の文字
//// 引数のチェック
lenb = str.GetLength();
if( lenb == 0 )
return work; // 空文字の場合
len = mbGetLength( str );
if( ( index <0 ) || ( index >= len ) )
return work; // index が範囲外の場合
if( count <1 )
return work; // count が範囲外の場合
//// メイン処理
for( lop = 0; lop <lenb; lop++ ){ // インデックスは 0 から
// 判断する文字を取り出す
scode = unsigned int( str[ lop ] ) & 0xff;
mcode = unsigned int( str[ lop ] ) & 0xff;
mcode = mcode <<8;
if( (lop + 1) <lenb ) // ASSERT対策:CStringの範囲を越えないように
mcode |= unsigned int( str[ lop + 1 ] ) & 0xff;
mcode &= 0xffff;
// 文字種別の判断
if( __isascii( scode ) != 0 ){
// 1バイト文字
cnt ++;
chrSize = 1;
}
else if( _ismbclegal( mcode ) != 0 ){
// 2バイト文字
cnt ++;
lop ++; // 強引にカウントアップ
chrSize = 2;
}
else{
// 認識できない文字
cnt ++;
chrSize = 1;
}
// 文字列の切り出し
if( cnt == index + 1 )
copyPos = cnt; // 指定された部分文字列の先頭に達した
if( copyPos != 0 ){
// コピー中
copyCnt = cnt - copyPos + 1;
if( copyCnt > count )
break; // 部分文字列が完成した
if( chrSize == 1 )
work += unsigned char(scode);
else{
work += unsigned char( (mcode & 0xff00) >> 8 );
work += unsigned char( (mcode & 0x00ff) );
}
}
}
return work; // 正常時
}
//---------------------------------------------------------------------------
// mbLeft()
// CString 内の先頭から指定された部分文字列を返します
// [in]
// str : 部分文字列を取り出す、元の文字列(CString のみ)
// count : 取り出す文字数(2バイト文字も1個と数えます)
// [out]
// 取り出した部分文字列
// [注意]
// この関数はmbGetLength(),mbMid() を利用しています
// count が範囲外の場合、空文字を返します
// count が文字数を越えている場合、str の終端までを返します
// すべての条件で正しい部分文字列を返すどうか検証していません
//
CString CVC5Dlg::mbLeft( CString& str, int count )
{
CString work = ""; // 取り出した部分文字列(戻り値)
//// 引数のチェック
if( count <1 )
return work; // count が範囲外の場合
//// メイン処理
work = mbMid( str, 0, count );
return work; // 正常時
}
//---------------------------------------------------------------------------
// mbRight()
// CString 内の末尾から指定された部分文字列を返します
// [in]
// str : 部分文字列を取り出す、元の文字列(CString のみ)
// count : 取り出す文字数(2バイト文字も1個と数えます)
// [out]
// 取り出した部分文字列
// [注意]
// この関数はmbGetLength(),mbMid() を利用しています
// count が範囲外の場合、空文字を返します
// count が文字数を越えている場合、str の終端までを返します
// すべての条件で正しい部分文字列を返すどうか検証していません
//
CString CVC5Dlg::mbRight( CString& str, int count )
{
int len; // 文字数
int index; // 取り出す先頭位置
CString work = ""; // 取り出した部分文字列(戻り値)
//// 引数のチェック
if( count <1 )
return work; // count が範囲外の場合
len = mbGetLength( str );
if( count > len )
count = len; // count が文字数より大きい場合
//// メイン処理
index = len - count;
work = mbMid( str, index, count );
return work; // 正常時
}
//---------------------------------------------------------------------------
|
|