fit_poly4
例:fit_poly4([@],[1],0.05,[2],[6],[7],4);
- 機能:
- N次多項式近似のデータの信頼区間の予測(注意:信頼区間はデータに対するもの)
- 書式:
- fit_poly4([ix],[iy],α,[oix],[y_l],[y_h],次数n )
- 解説:
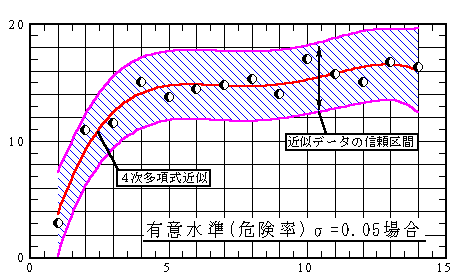
- 有意水準(危険率)α (0<α<1)の時、n次多項式で最小二乗法近似をする場合のデータの信頼区間を予測します。
有意水準(危険率)αが同じであれば、データの信頼区間は、近似式の信頼区間(関数fit_poly3()とfit_one3()で得る)よりかなり広いです。
求めたい信頼区間のX値は、引数[oix]で与えられます。
[ix],[iy] ・・・・・・・・・・・・・・・ 近似点列のXY座標の入力数値組([ix]は@で代替可能)
α ・・・・・・・・・・・・・・・ 信頼区間の大きさを決める有意水準(危険率)の指定 (0<α<1)
[oix] ・・・・・・・・・・・・・・・ 求めたい信頼区間のX値入力数値組(fit_poly1()の[ox]を使用すると便利)
[y_l] ・・・・・・・・・・・・・・・ 結果の信頼区間の下側Y値の出力数値組
[y_h] ・・・・・・・・・・・・・・・ 結果の信頼区間の上側Y値の出力数値組
次数n ・・・・・・・・・・・・・・・ 使用する近似多項式の次数の指定
参照:fit_poly3()
| return |